
Three types of methods are distinguished, each with their own advantages and disadvantages. Since not all methods are easy to implement, some authors have provided on-line access to their source-code. An overview of available methods can be found here.
Static Methods
Methods that are applied to images with a fixed parameter setting are either based on low-level statistics or on the physics-based dichromatic reflection model. The first type of methods include the Grey-World, the White-Patch and the Grey-Edge methods, integrated in one framework by van de Weijer et al. The Grey-World algorithm assumes that, under a white light source, the average color in a scene is achromatic. This implies that any deviation of the average color away from grey is caused by the effects of the light source. In opponent color space, this means that the bulk of the image colors of an image under a white light source are aligned with the intensity axis (see the figure below), and the bulk of the image colors of an image under arbitrary light source are aligned with the color of the light source. The White-Patch algorithm assumes that the maximum response in an image is caused by a perfect reflectance (i.e. a white patch, see the figure below).
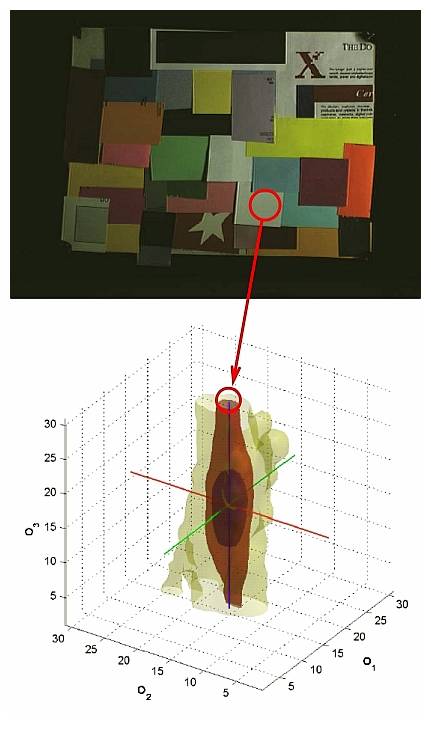
In practice, this assumption is alleviated by considering the color channels separately, resulting in the max-RGB algorithm. The Grey-Edge algorithm is based on the same principles, but uses derivatives of image rather than pixels. Another example of a method using low-level statistics is proposed by Chakrabarti et al.. This method explicitly models the spatial dependencies between pixels, learning dependencies between pixels in an efficient way. Source-code of Grey-World, White-Patch and Grey-Edge methods can be found here, the method using spatial correlations can be found here.
Physics-based methods are the second type of static algorithms. Such methods often adopt the more general dichromatic reflection model rather than the Lambertian reflectance model. The main difference between the two is the addition of a specular component, which is used to model the reflectance in the viewing direction. These methods use information about the physical interaction between the light source and the objects in a scene. The underlying assumption of most methods is that all pixels of one surface fall on a plane in RGB color space. Multiple of such surfaces result in multiple planes, so the intersection between the planes can be used to compute the color of the light source. One method based on this principle is proposed by Tan et al., and uses a color space called “Inverse-intensity Chromaticity Space” to recover specularities. These highlights are subsequently used to recover the color of the light source. The source-code of this method can be found here.
Gamut Mapping
Gamut mapping is based on the assumption, that in real-world images, for a given illuminant, only a limited number of colors are observed. Consequently, any unexpected variation in the colors of an image is caused by a deviation in the color of the light source. The limited set of colors that can occur under a given illuminant is learned off-line and is called canonical gamut. This canonical gamut is learned from a training set (e.g. a set of real-world images with ground truth illuminant or a set of hyperspectral surfaces). This set can contain any number of images or patches, but should give an accurate representation of colors that can occur in the test environment. Then, for any input image, an input gamut is constructed, that is used as representative set of colors for the light source used to record the input image. Using the canonical gamut and the input gamut, a set of mappings can be computed that map the input gamut completely inside the canonical gamut. Since multiple mappings will be feasible (hence the feasible set in the figure below), one of these mappings has to be selected as the estimated illuminant. Finally, this selected mapping is used to construct the output image.
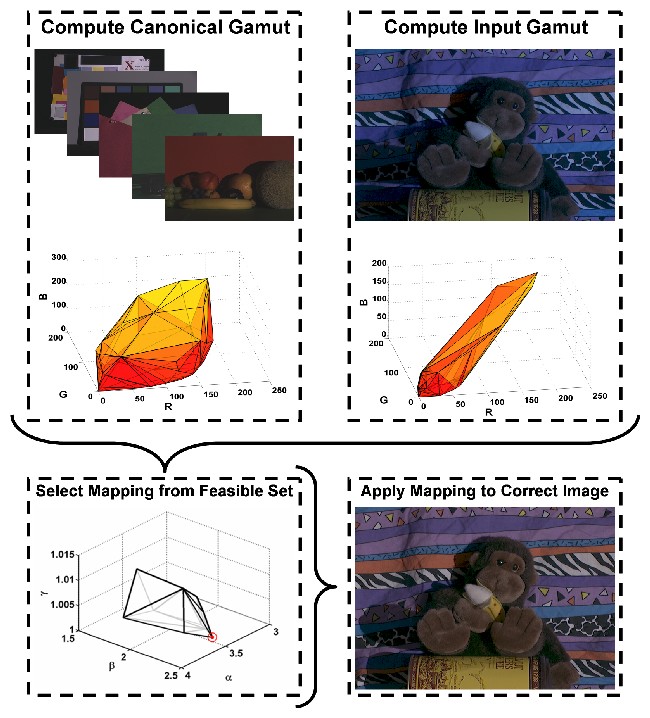
One implementation of this algorithm was made available by Kobus Barnard in 2002. This version enables the user to apply segmentation as preprocessing step, which has been shown to be very beneficial for the gamut mapping algorithm. The software can be found here. Another version was made available by Arjan Gijsenij, and incorporates image derivative structures and enables different fusion strategies. This version can be found here.
Learning-based Methods
Finally, we distinguish learning-based methods, i.e. algorithms that estimate the illuminant using a model that is learned on training data. One line of research focuses on applying learning or regression techniques to some feature vector extracted from the input image, e.g. Agarwal et al. or Xiong et al. Other types of algorithms using low-level features are based on the Bayesian formulation, e.g. Rosenberg et al. or Gehler et al. Source-code for the latter method can be obtained here.
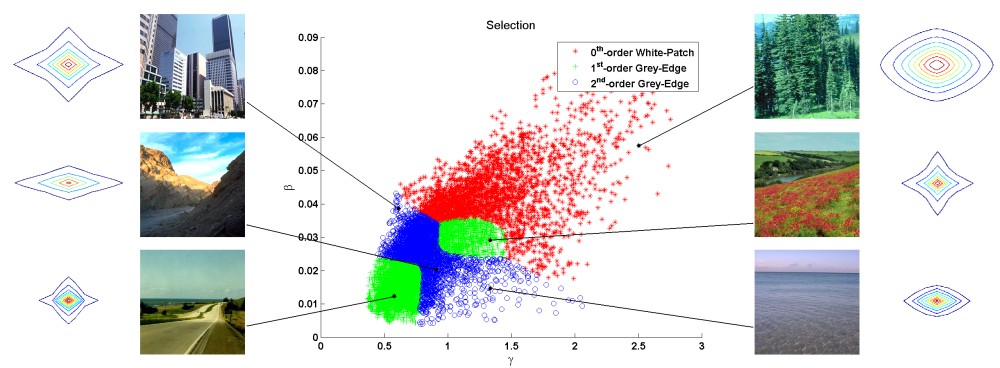
Despite the large variety of available methods, none of the color constancy algorithms can be considered as universal. To make full use of the strong points of all algorithms, and ignore the weak points as much as possible, multiple algorithms will have to be considered at once. Several combination and selection strategies have emerged since one 1999. One influential paper by Gijsenij and Gevers focused on selecting the most appropriate algorithm based on image statistics. In 2007, Gijsenij and Gevers presented this paper at the IEEE Conference on Computer Vision and Pattern Recognition, and in 2011 their work was published in IEEE Transactions on Pattern Analysis and Machine Intelligence (click here for the paper). Source-code for this method is available.
Another influential line of research focuses on using semantic information for the estimation of the illuminant. For instance, Bianco et al. use indoor/outdoor classification to select the optimal color constancy algorithm given an input image. Another example is proposed by Lu et al., and explicitly uses 3D scene information for the estimation of the color of the light source. Finally, Joost van de Weijer et al. propose to cast illuminant hypotheses that are generated and evaluated based on the likelihood of semantic content. Using prior knowledge about the world, an illuminant estimate is selected that results in colors that are consistent with the learned model of the world. Source-code of this method can be found here.
Color Constancy by GANs
 Generative Adversarial Networks (GANs) have demonstrated remarkable results on many image-to-image translation problems. In that sense, Das et al. formulate the color constancy task as an image-to-image translation problem using GANs. By conducting a large set of experiments on different datasets, they provide an experimental survey on the use of different types of GANs to solve for color constancy i.e. CC-GANs (Color Constancy GANs).
Generative Adversarial Networks (GANs) have demonstrated remarkable results on many image-to-image translation problems. In that sense, Das et al. formulate the color constancy task as an image-to-image translation problem using GANs. By conducting a large set of experiments on different datasets, they provide an experimental survey on the use of different types of GANs to solve for color constancy i.e. CC-GANs (Color Constancy GANs).